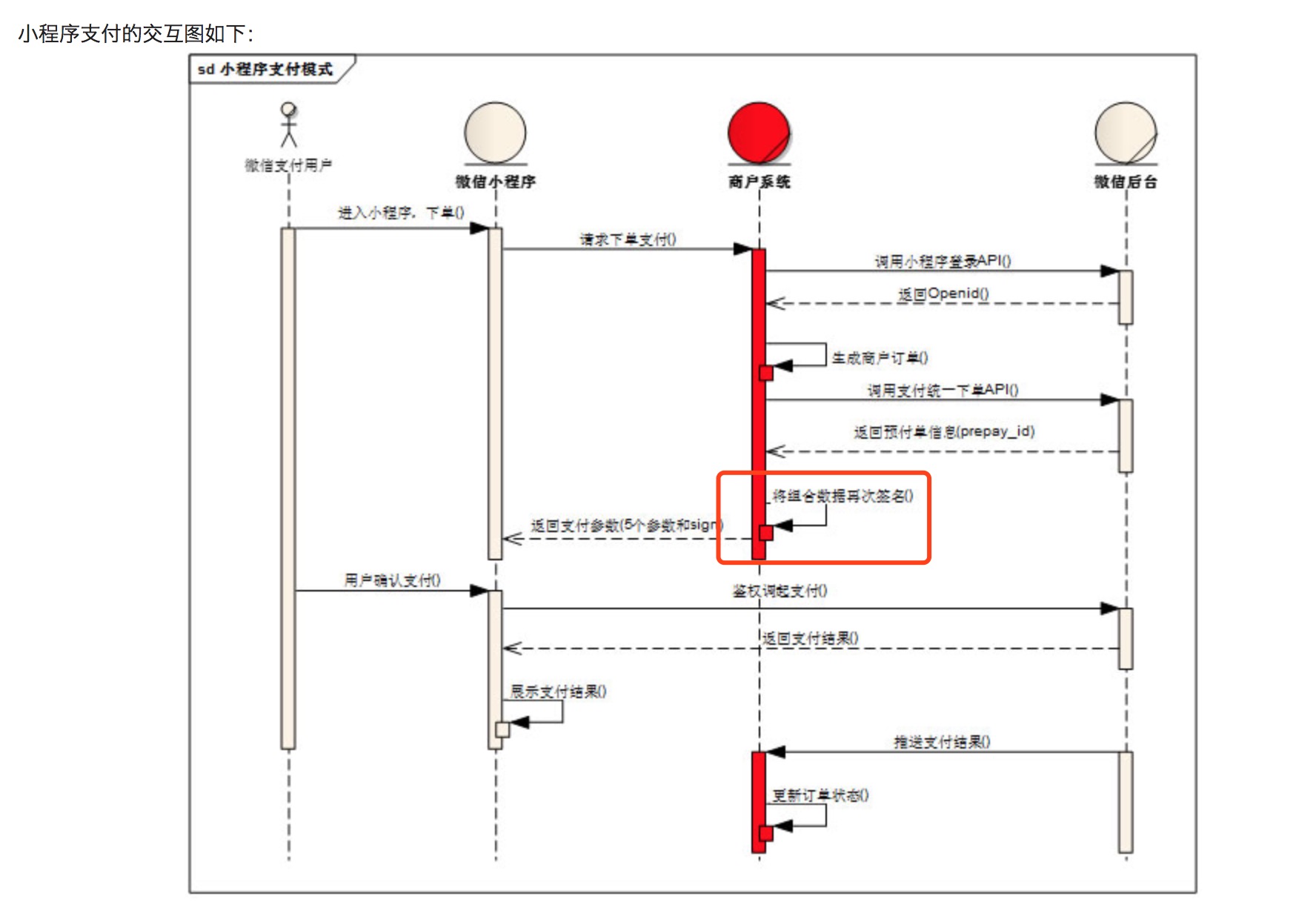
在完成大概所有的CRUD和支付功能后…开始去玩…看起来最高大上的”语音识别”功能…我们最终选取的语音识别平台是百度…原因嘛…因为它免费…不过话又说起来…百度的语音识别接起来…还真挺简单的…直接提供了pip包,非常方便集成在flask框架中,我按照了示例…自己测试了文件上传…又调用百度语音识别api成功后…觉得自己大事已成…万万没想到的是…微信的语音文件格式并不可以被百度语音直接识别…WTF!怎么办…当时考虑使用讯飞…以为它可以转万能的语音格式…官方查阅之…原来不是…那就只有一种办法了…自行转码…于是又去搜索python的音频转码库…然而都没有对微信那种语音文件格式的支持…所以没办法了…到了这里…要么使用C语言…自己编写转码库和程序…让C调用…要么…嗯…使用第三方外部转码程序…好在Python和Unix/Linux对调用第三方应用支持比较好,这点没什么难度…那么话又说回来了…微信的语音文件到底是什么格式呢?百度之…大佬们众说纷坛…不过一个比较可信的主流的观点是SILK文件格式…嗯…于是各种搜索…终于让我找到了一款神器:ffmpeg万能解码器,支持丰富cli处理!在研究使用ffmpeg的时候…发现了 一个有趣的词…Hall of Shame有兴趣的朋友们可以自己去看看鹅厂的黑历史…然鹅…一番折腾后发现…ffmpeg并没有支持silk音频的解码库…需要自己额外下载…WTF!后来我又百度之…终于…发现了这位大佬,传送门,于是我按照文档…发现…居然告诉我这个
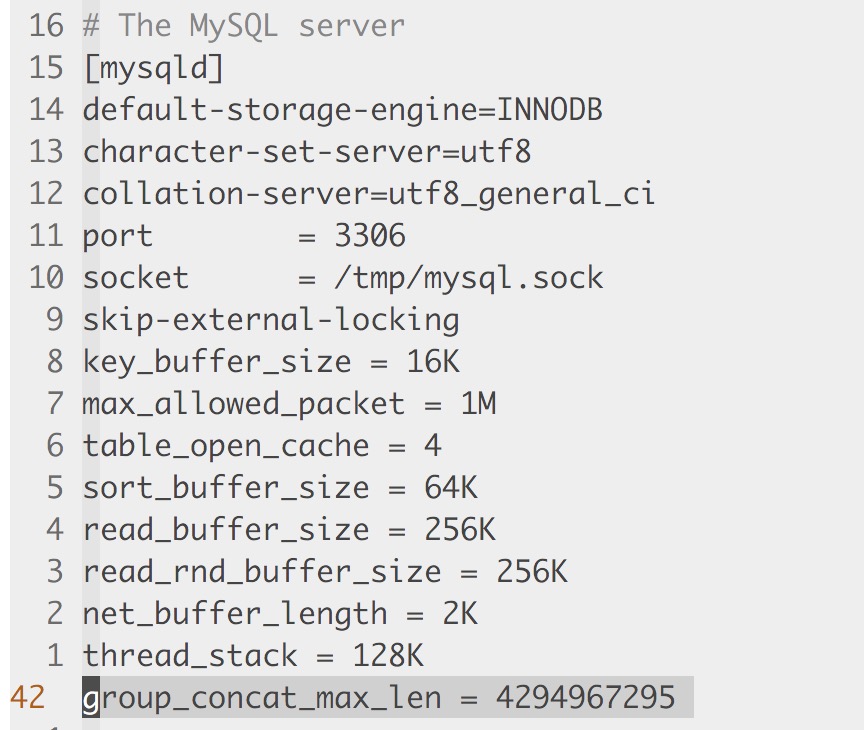
在mysql中,有个函数叫“GROUP_CONCAT”,平常使用可能发现不了问题,然而一旦数据量增大时,会发现内容被截取了!!!是的,你没看错,就是被截取了!!真的是非常令人蛋疼的问题呀,尤其是在类似聚合分组的业务,将数据反馈给客户端时,就更为严重了!多番查找折腾后发现,原来… MYSQL内部对这个是有设置的,默认不设置的长度是1024,可以通过使用show variables like "group_concat_max_len命令来查看该变量值
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
查阅官方的手册后,官方时如此介绍的:
For beginners, a useful startup option is --safe-updates (or --i-am-a-dummy, which has the same effect). It is helpful for cases when you might have issued a DELETE FROM *tbl_name* statement but forgotten the WHERE clause. Normally, such a statement deletes all rows from the table. With --safe-updates, you can delete rows only by specifying the key values that identify them. This helps prevent accidents.
You are not permitted to execute an UPDATE or DELETE statement unless you specify a key constraint in the WHERE clause or provide a LIMIT clause (or both)
The server limits all large SELECT results to 1,000 rows unless the statement includes a LIMIT clause
The server aborts multiple-table SELECT statements that probably need to examine more than 1,000,000 row combinations
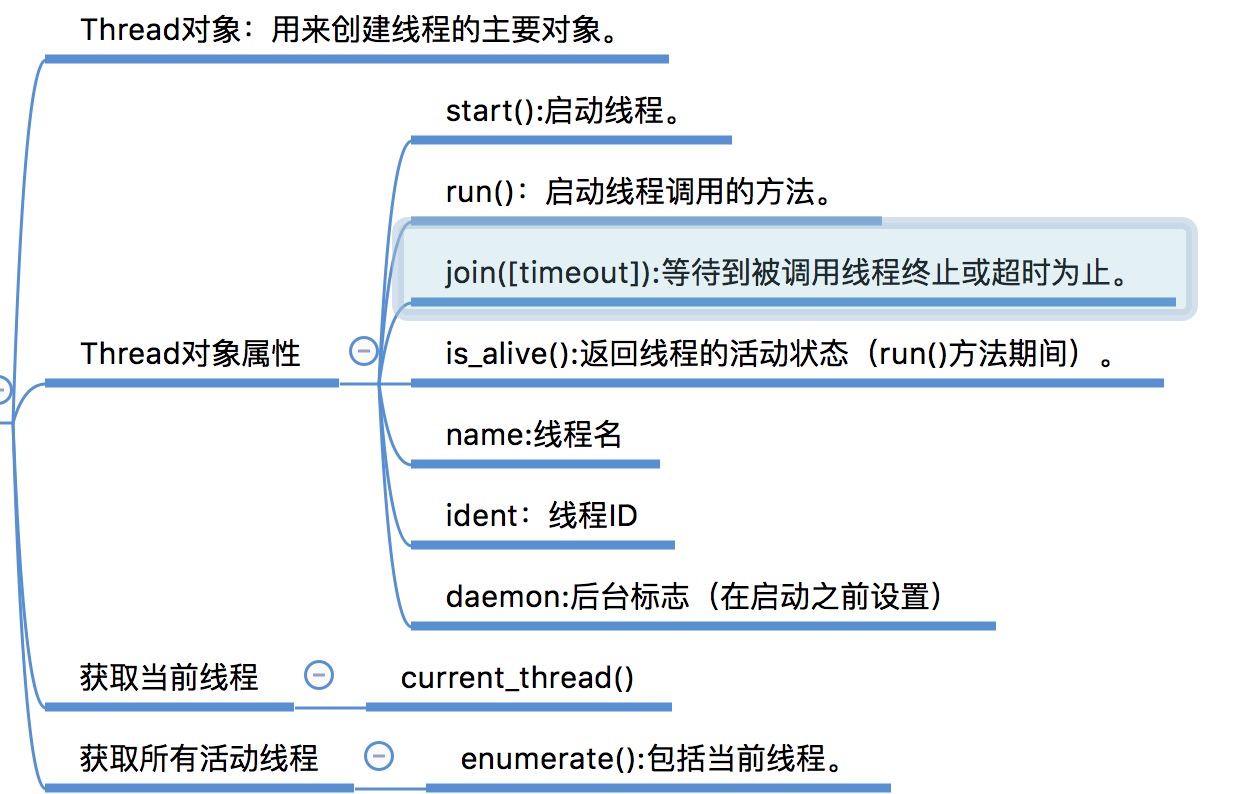
There are two ways to specify the activity: by passing a callable object to the constructor, or by overriding the run() method in a subclass
下面先介绍下Thread对象相关属性和方法,以及线程的创建方式
第一种方式:继承Thread类并重写run()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classMyThread(threading.Thread): def__init__(self): super().__init__() defrun(self): s = 0 for i in range(30): s += i; time.sleep(0.1) print(s) th = MyThread()
第二种方式:在实例化Thread对象时传入线程的运行目标任务(一个函数)
1 2 3 4 5 6 7 8
defthfun(): s = 0 for i in range(30): s += i; time.sleep(0.1) print(s)