走近Python的加解密
相关概念
数据加密技术
所谓数据加密(Data Encryption)技术是指将一个信息(或称明文,plain text)经过加密钥匙(Encryption key)及加密函数转换,变成无意义的密文(cipher text),而接收方则将此密文经过解密函数、解密钥匙(Decryption key)还原成明文。 ——以上内容节选自【百度百科)】
信息编解码技术
编码是信息从一种形式或格式转换为另一种形式的过程,也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程。——以上内容节选自 【百度百科)】
从以上定义可以总结如下:
- 数据加密和信息编码都会对原有数据进行一定的转换
- 两者进行转换的目的是不同的:
- 数据加密技术更多的出于信息安全的考量
- 数据的编解码更多的出于计算机传输和存储和解析的考量
因此我们平时在工作交流和表达过程中所说的“Base64加密”其实并非加密,而只是为了某种传输需要将数据明文进行了某种转换。转换的编解码规则是公开的,理论上,任何了解Base64编解码规则的同学,都可以将Base64编码串解码后得到原有数据!
消息摘要算法
消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,目前可以被解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。——以上内容节选自【百度百科)】
在实际工作中我们常用的信息摘要算法有MD5和SHA1
后端开发童鞋经常提到:用户密码不可以明文保存,要使用MD5算法对用户密码进行”加密”后再存至数据库。
同样,这里”加密”也并非我们严格定义上的”加密”,使用MD5处理的原因是信息摘要过程是不可逆,且中间不需要任何密钥的参与!理论上攻击者无法通过信息摘要算法得到结果反推出原始数据,这个特性使得信息摘要算法的主要用途是:
验证数据的完整性和一致性
对数据进行签名及校验
在了解了有关概念和定义后,我们就可以进一步探讨数据加密技术了。
数据加密算法根据加密和解密时是否使用同一密钥可分为
对称加密算法:在加密和解密时使用的是同一个密钥
常见对称加密算法有:DES算法(安全性上不如AES,逐步被AES替代), AES算法
非对称加密算法:在加密和解密时使用不同密钥
常见的非对称算法:RSA算法,椭圆曲线算法(又称ECC,被广泛用于区块链业务中,被视为RSA算法的有力挑战者)
本文以当前企业应用中最为常见的AES算法和RSA算法进行介绍,相关代码可在我的github repo中找到
AES加解密算法
流程
AES加解密的流程,先以我看到的一张图描述(如有侵权,请联系博主删除)
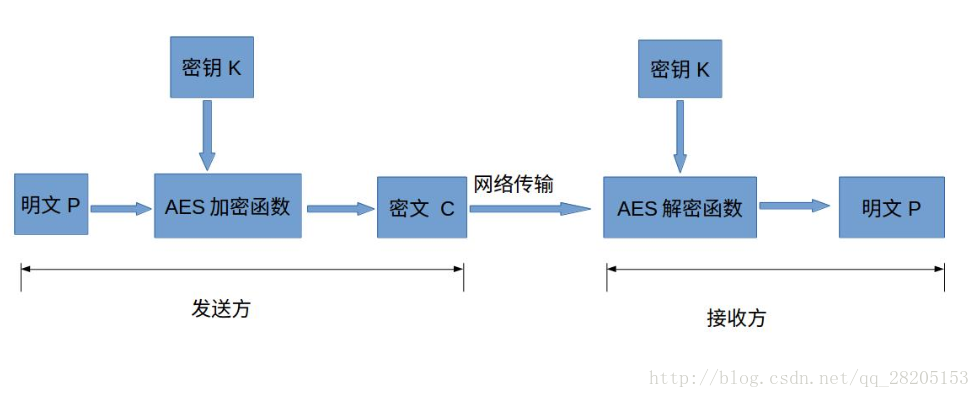
相关概念
密钥
密钥是AES算法实现加密和解密的根本。对称加密算法之所以对称,是因为这类算法对明文的加密和解密需要使用同一个密钥。
AES支持三种长度的密钥:128位,192位,256位
如果对于密钥没有一个直观印象,可以将密钥理解为发送方和传输方共同拥有的钥匙。
填充
要想了解填充,先要了解AES的分组加密特性
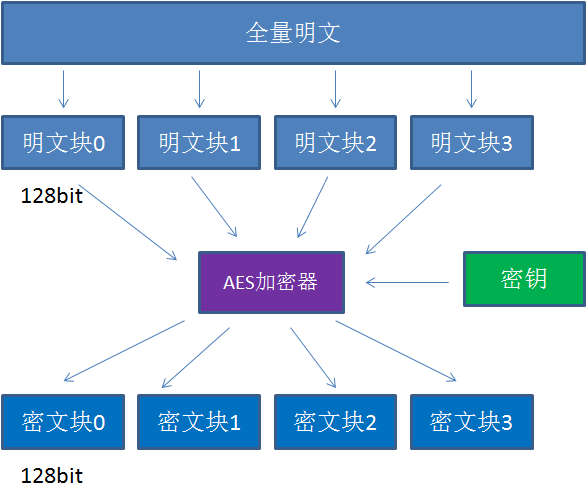
AES算法在对明文加密的时候,并不是把整个明文一股脑加密成一整段密文,而是把明文拆分成一个个独立的明文块,每一个明文块长度128bit。假如一段明文长度是196bit,如果按每128bit一个明文块来拆分的话,第二个明文块只有64bit,不足128bit,这个时候就需要对明文块进行填充。根据填充算法的不同有以下几种常见的填充方式:
- PKCS#7Padding:假设数据长度需要填充n(n>0)个字节才对齐,那么填充n个字节,每个字节都是n;如果数据本身就已经对齐了,则填充一块长度为块大小的数据,每个字节都是块大小
- ZeroPadding:数据长度不对齐时使用0填充,否则不填
- PKCS#5Padding:PKCS7Padding的子集,块大小固定为8字节
模式
AES的工作模式,体现在把明文块加密成密文块的处理过程中。AES加密算法提供了五种不同的工作模式:CBC、ECB、CTR、CFB、OFB
其中最为常见且推荐使用的便是CBC模式了
过程描述
基于此前密钥就是钥匙的假设,可以认为加密过程理解为将数据装进一个带锁的箱子,这个锁只有钥匙(密钥)拥有者才能打开,而相应的解密过程就是使用密钥打开上锁的箱子并取出其中数据
代码
代码参考简书文章,基于pycryptodome使用Python编写
加密流程
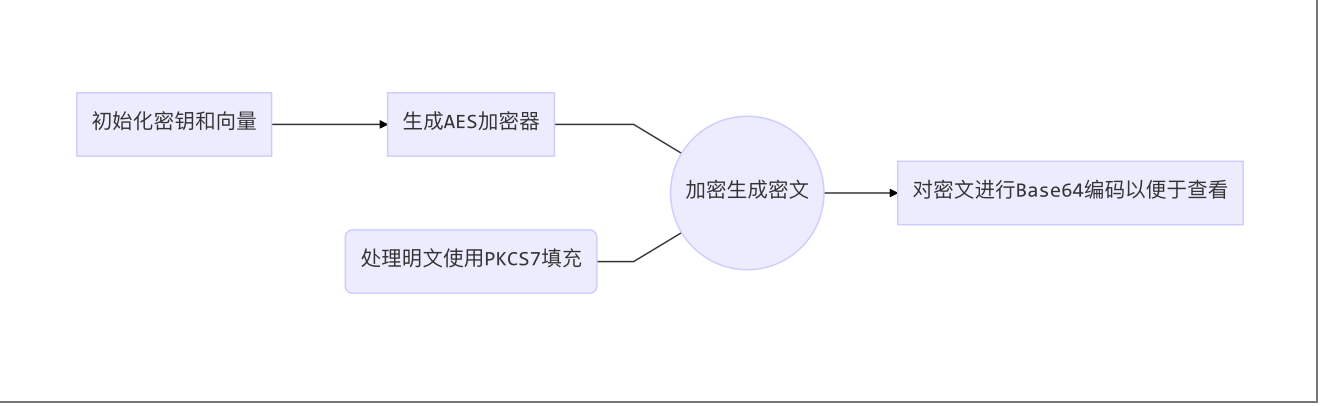
解密流程

以上部分的具体代码可在我的github repo上找到
RSA加解密算法
流程与场景
RSA加解密的流程,先以我看到的一张图描述(如有侵权,请联系博主删除)
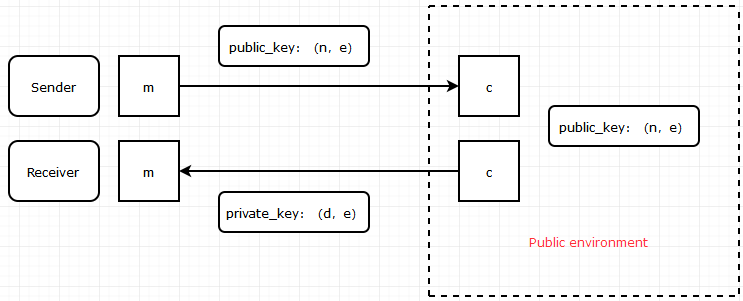
其中public_key表示公钥,private_key表示私钥。
我们举两个栗子吧
场景1:
Bob要写情书(明文)给Alice,但是Alice希望情书内容不能被人自己父母发现,于是就采用了RSA加密的方式来传递情书。
Alice先用RSA生成了一对密钥(有一个公钥,和一个私钥),Bob拿走公钥对情书A(明文)进行加密,生成情书B(密文)。Alice拿到情书B后,用手上的密钥,破解了B,把B还原为原来的A。这样一来,其他人因为没有私钥,无法查看他们之间的甜言蜜语,只有Alice一个人知道其中的秘密
场景2:
现在Alice要给Bob回情书,告诉他今晚12点村头桥下约会,那么,如何让Bob知道情书真是Alice写的呢?注意,Alice手上有私钥,Bob手上有公钥。这时,Alice把情书用私钥进行签名,带着签名和情书内容一同寄出给Bob,Bob拿着公钥验证签名,发现确实是Alice写的,这样一来,他就完全可以相信情书的内容了。
这里的签名,本质上,是在允许信息内容别第三者发现的情况下,为了让信息接受者可以验证信息的真实性
上述两个场景的总结:
场景一:公钥加密,私钥解密
场景二:私钥签名,公钥验证。
原理及验证
有关RSA算法的数学原理极其验证过程不是本文的重点,此部分内容建议阅读阮一峰老师的博文:
代码
根据RSA算法的两个不同应用场景,但无论何种场景都需要生成密钥对,这是RSA算法的基础,这里介绍两种生成密钥对的方法:
方法1:使用openSSL工具
1 | # 生成1024位的私钥 |
有关openSSL工具的更多用法可查阅《openssl命令使用》
方法2:通过pycryptodome库自行创建
1 | from Crypto.PublicKey import RSA |
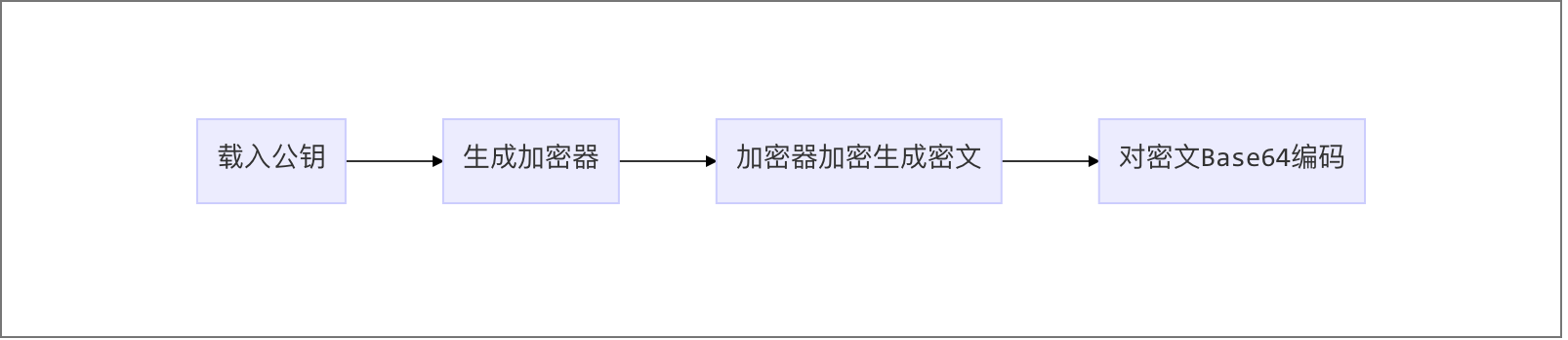
场景1
加密过程
解密过程
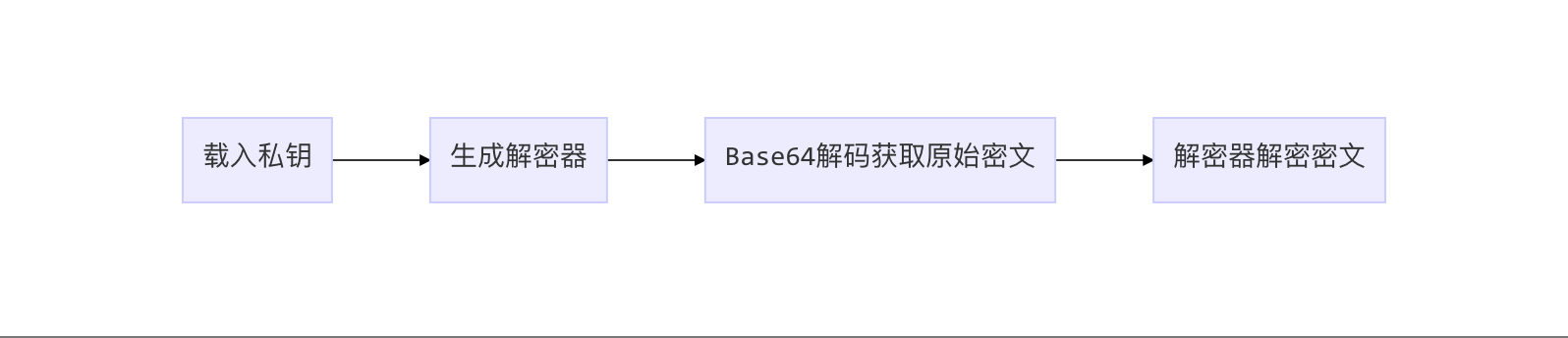
场景2
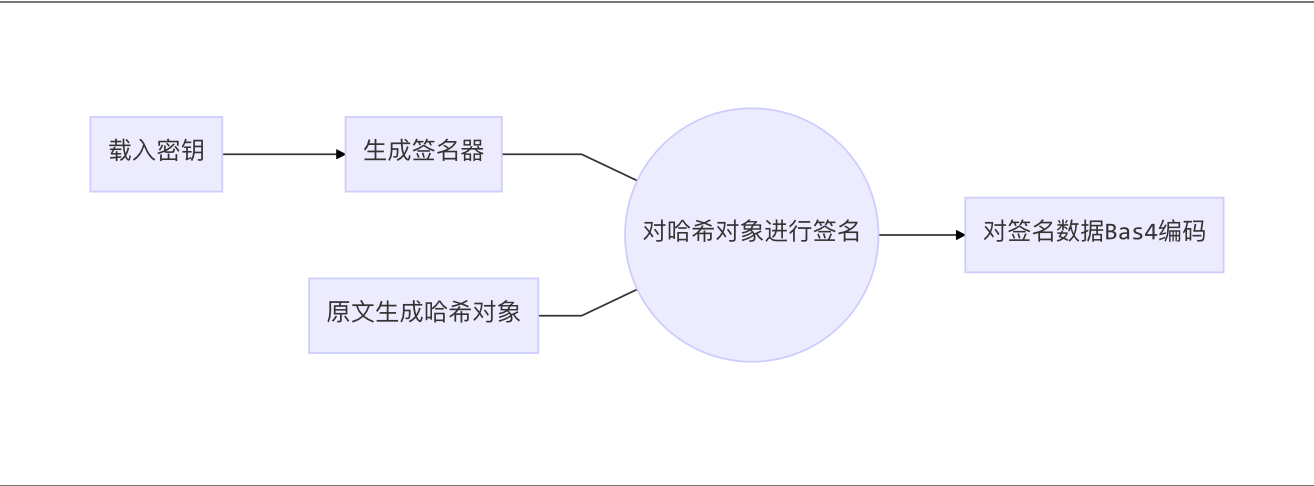
签名过程
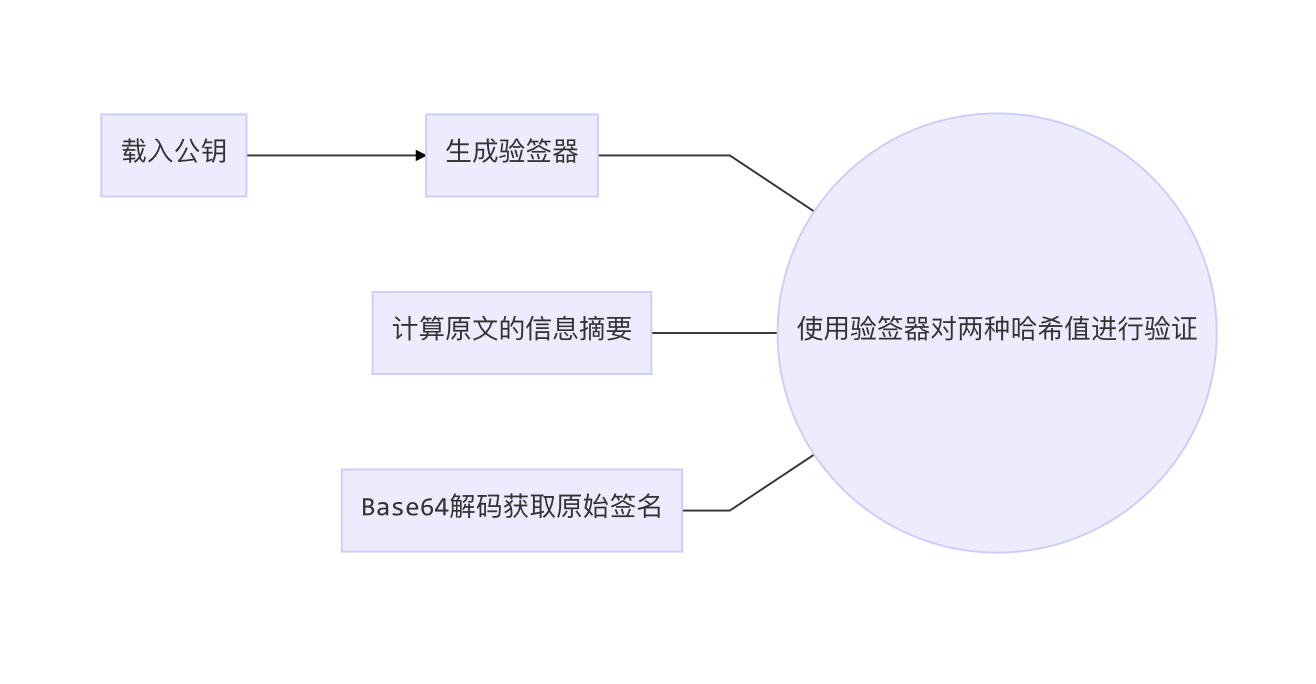
验签过程
以上部分的具体代码可在我的github repo上找到
参考列表
AES部分,以下排名不分先后
- 漫画:什么是AES算法?)
- AES加密的四种模式详解(https://www.cnblogs.com/liangxuehui/p/4651351.html)
- AES五种加密模式
- python3 AES 加密
- AES模式和填充
- 三种填充模式的区别(PKCS7Padding/PKCS5Padding/ZeroPadding)
- AES加密算法的详细介绍与实现
RSA部分,以下排名不分先后
结尾
如果你喜欢我的文章,请扫描以下二维码,给我小额赞赏,如果没有特殊声明,赞赏…将用于改善我的个人生活~比如:奶茶,咖啡,酸奶或其它零食~😁